Every time a fraud detection system flags a suspicious transaction, a recommendation engine suggests a product, or a diagnostic model identifies an anomaly, inference is happening. It is one of the most fundamental operations in data science and machine learning.
The Intuitive Definition: Learning From the Few to Understand the Many
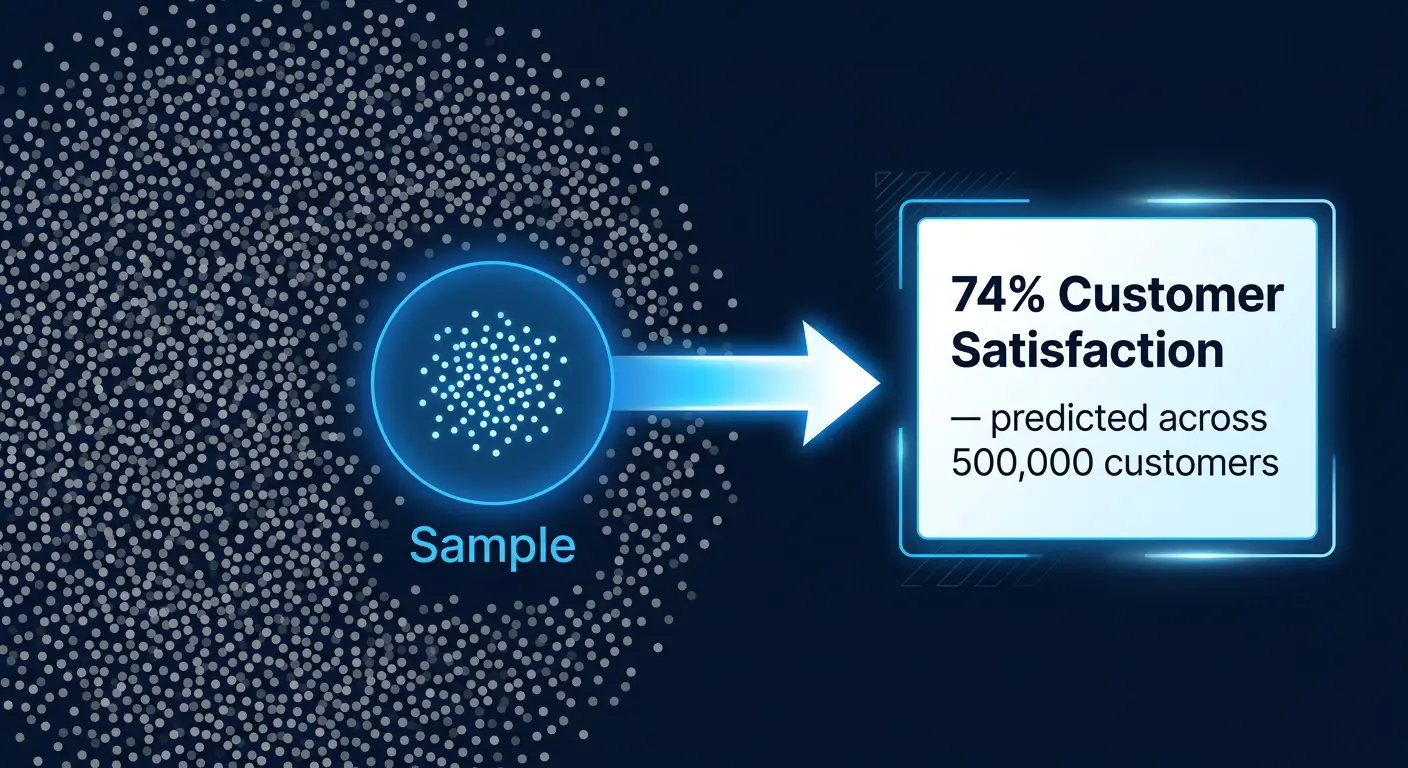
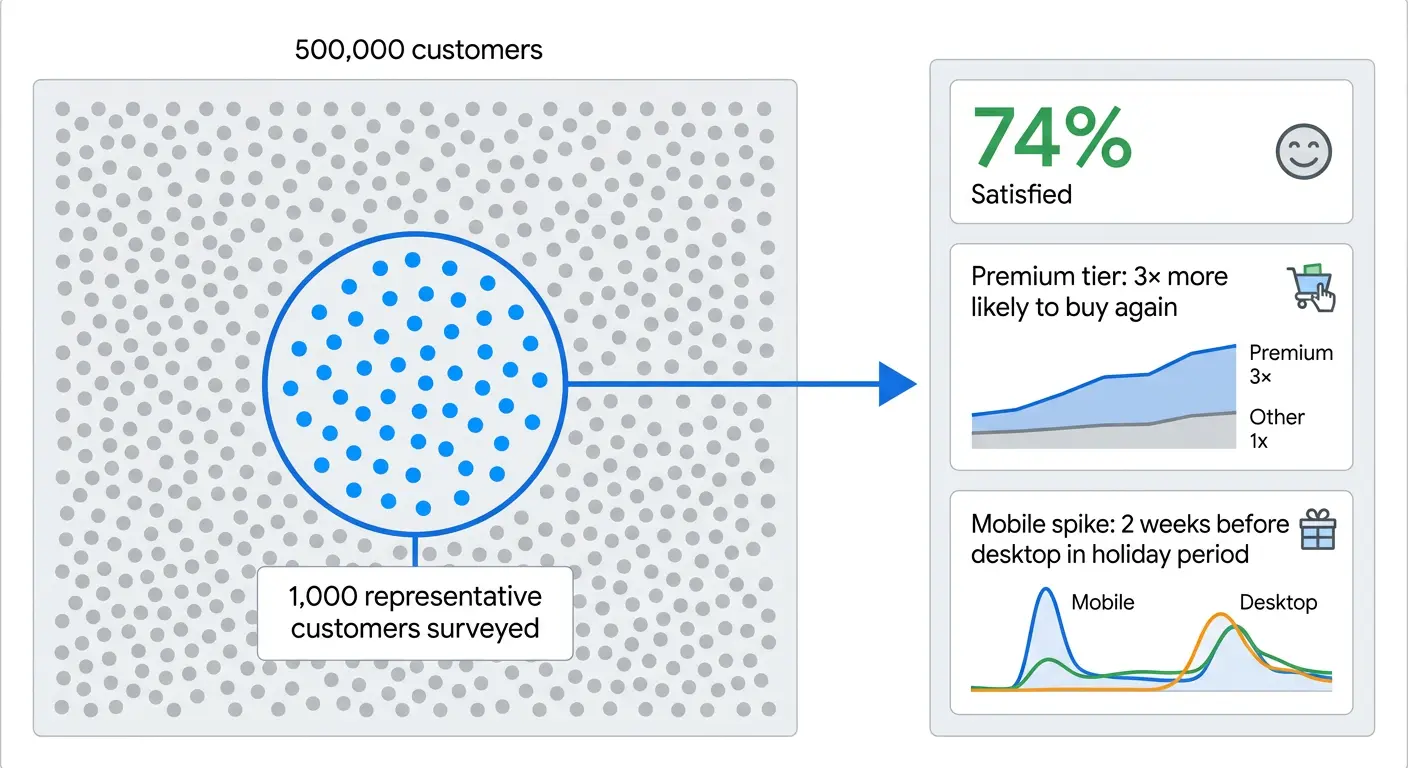
Imagine understanding the satisfaction of 500,000 customers by surveying 1,000. That is inference.
Inference is the process of drawing meaningful conclusions about a larger population or system based on a smaller, representative sample or observed dataset.
Formal Definition: Inference Data in Analytics
Inference data refers to the data produced by drawing conclusions, making predictions, or generalising based on observed feature datasets.
It is foundational to:
- Statistical reasoning: estimating population parameters from samples
- Machine learning predictions: applying trained models to new inputs
- Business analytics: deriving actionable insights from operational data
- Scientific research: generalising experimental findings to broader populations
Inference in Machine Learning: Training vs. Inference
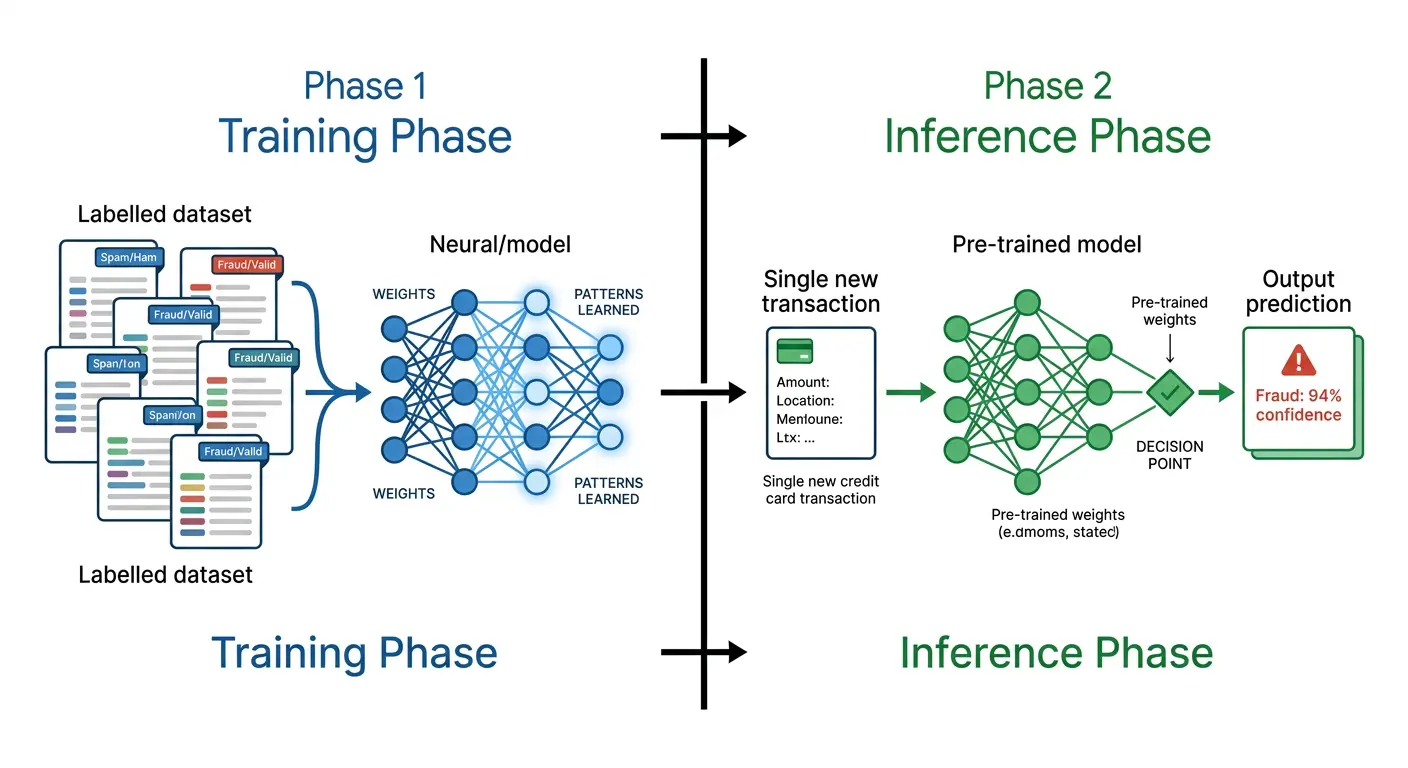
The Machine Learning Lifecycle
The machine learning lifecycle divides into two distinct phases:
- Training phase: the model learns patterns from labelled data, adjusting its internal parameters to minimise prediction error
- Inference phase: the trained model applies those learned patterns to new, unseen data in real time to generate predictions, classifications, or recommendations
Why Inference Performance Is the Real Measure
Training accuracy is necessary but not sufficient. A model that scores 99% on training data but fails on new inputs has overfitted. It has memorised rather than learned. Overfitting means the model cannot generalise, and generalisation is the entire purpose of inference.
Inference quality is the actual measure of business value. A model is only as useful as its ability to make accurate, reliable predictions on data it has never encountered before.
Statistical Inference: Two Key Types
Statistical inference operates at two levels:
- Descriptive inference: conclusions are limited to the observed sample. The findings describe what was measured, without extending beyond it.
- Generalisable inference: conclusions extend to the broader population from which the sample was drawn, accompanied by a stated confidence level and margin of error.
Both forms require disciplined sampling methodology. Without a representative sample, neither form of inference can be trusted.
The Limits and Responsibilities of Inference
| Risk | Description | Mitigation |
|---|---|---|
| Sampling bias | Sample doesn’t represent population | Stratified, random sampling |
| Small sample variance | Insufficient data | Increase sample size; report confidence intervals |
| Distribution shift | Population changes after training | Regular retraining and monitoring |
| Overfitting | Model memorises training data | Regularisation, cross-validation |
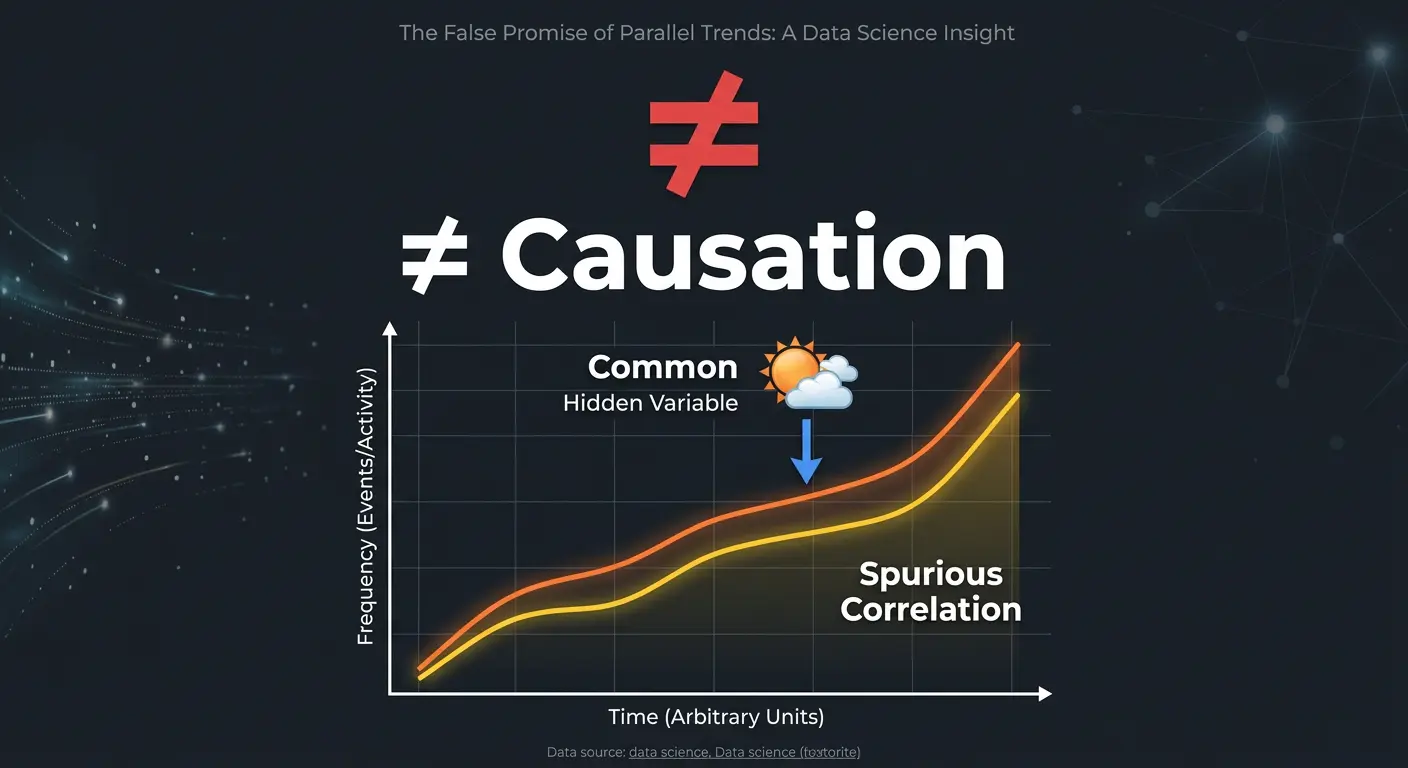
| Confounding variables | Unmeasured factors distort inferences | Causal analysis, controlled study design |
Inference vs. Causality: An Important Distinction
| Concept | Core Question | Example Output |
|---|---|---|
| Inference | What is likely true about the population? | “74% of customers are satisfied” |
| Causality | What caused this outcome? | “Faster delivery caused a 12-point increase” |
Inference tells you what. Causality tells you why. Effective analytics programmes develop both capabilities, using inference to identify patterns and causal analysis to understand the mechanisms behind them.
Key Takeaway
Inference is the engine beneath every predictive model, recommendation system, and population-level analysis. It is disciplined, probabilistic reasoning applied to real-world uncertainty. It is the foundation of every intelligent, data-driven decision.

Ready to build ML capabilities that deliver real-world results?
Your Partner Technologies builds data science and machine learning solutions that turn inference into competitive advantage.
Talk to Us →